#FactCheck: Viral video claims Ahmedabad plane crash but actually a Hollywood Movie Clip
Executive Summary:
A viral video claiming the crash site of Air India Flight AI-171 in Ahmedabad has misled many people online. The video has been confirmed not to be from India or a recent crash, but was filmed at Universal Studios Hollywood on a TV or movie set meant to look like a plane crash set piece for a movie.

Claim:
A video that purportedly shows the wreckage of Air India Flight AI-171 after crashing in Ahmedabad on June 12, 2025, has circulated among social media users. The video shows a large amount of aircraft wreckage as well as destroyed homes and a scene reminiscent of an emergency, making it look genuine.

Fact check:
In our research, we took screenshots from the viral video and used reverse image search, which matched visuals from Universal Studios Hollywood. It became apparent that the video is actually from the most famous “War of the Worlds" set, located in Universal Studios Hollywood. The set features a 747 crash scene that was constructed permanently for Steven Spielberg's movie in 2005. We also found a YouTube video. The set has fake smoke poured on it, with debris scattered about and additional fake faceless structures built to represent a scene with a larger crisis. Multiple videos on YouTube here, here, and here can be found from the past with pictures of the tour at Universal Studios Hollywood, the Boeing 747 crash site, made for a movie.


The Universal Studios Hollywood tour includes a visit to a staged crash site featuring a Boeing 747, which has unfortunately been misused in viral posts to spread false information.

While doing research, we were able to locate imagery indicating that the video that went viral, along with the Universal Studios tour footage, provided an exact match and therefore verified that the video had no connection to the Ahmedabad incident. A side-by-side comparison tells us all we need to know to uncover the truth.


Conclusion:
The viral video claiming to show the aftermath of the Air India crash in Ahmedabad is entirely misleading and false. The video is showing a fictitious movie set from Universal Studios Hollywood, not a real disaster scene in India. Spreading misinformation like this can create unnecessary panic and confusion in sensitive situations. We urge viewers to only trust verified news and double-check claims before sharing any content online.
- Claim: Massive explosion and debris shown in viral video after Air India crash.
- Claimed On: Social Media
- Fact Check: False and Misleading
Related Blogs

Executive Summary:
Amid the ongoing conflict in West Asia involving the United States, Israel and Iran, a video is being widely circulated on social media with the claim that Iran attacked the headquarters of tech giants Apple and Microsoft in Israel. The clip shows a building engulfed in flames, with firefighters attempting to douse the fire. However, research by the CyberPeace found that the viral video is AI-generated and is being falsely linked to the ongoing conflict to spread misinformation.
Claim:
An Instagram user ‘bharat_updatenews’ shared the video on March 19, 2026, claiming that Iran had launched an attack on major tech company headquarters, including Apple and Microsoft, in Israel. The post suggested that the incident had raised serious security concerns and was being widely reported by international media.
Link: https://www.instagram.com/bharat_updatenews/reel/DWEUhLEAKaw
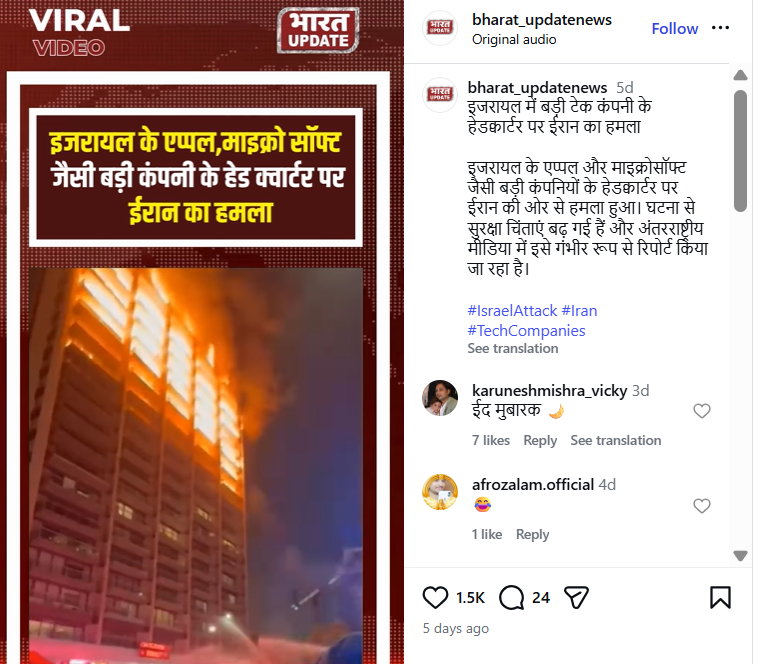
Fact Check:
To verify the claim, we extracted keyframes from the viral video and conducted a reverse search using Google Lens. During this process, we found the same video on a TikTok account named ‘dailyupdate122’, where it had been uploaded on March 15, 2026.
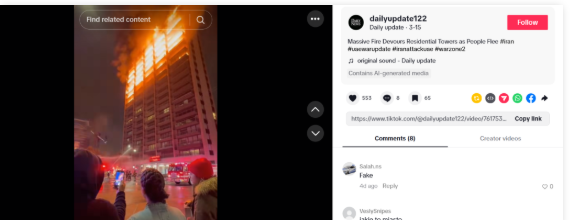
The video on this account was clearly labelled as “AI-generated media.” The account also featured several other AI-generated videos, raising doubts about the authenticity of the viral clip. Following this, we analysed the video using the AI detection tool Hive Moderation. The results indicated that the video is nearly 100 percent AI-generated. The tool further suggested with over 98 percent probability that the clip may have been created using OpenAI’s Sora or a similar AI video generation model.
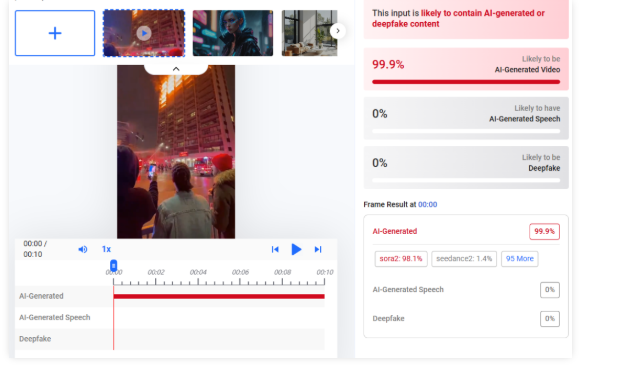
Conclusion:
The viral claim that Iran attacked Apple and Microsoft headquarters in Israel is false. The video circulating online is AI-generated and has no connection to the ongoing conflict in West Asia.

A video circulating on social media claims that British Prime Minister Keir Starmer was forcibly thrown out of a pub by its owner. The clip has been widely shared by users, many of whom are drawing political comparisons and questioning democratic norms. However, research conducted by Cyber Peace Foundation has found that the viral claim is misleading. Our research reveals that the video dates back to 2021, a time when Keir Starmer was not the Prime Minister of the United Kingdom, but the leader of the opposition Labour Party.
Claim
On January 12, 2026, a video was shared on social media platform X (formerly Twitter) with the claim that British Prime Minister Sir Keir Starmer was asked to leave a pub by its owner. The post suggests that the pub owner was unhappy with Starmer’s performance and contrasts the incident with how political dissent is allegedly handled in India. The viral video, approximately 32 seconds long, shows a man angrily confronting Keir Starmer in English, stating that he had supported the Labour Party all his life but was disappointed with Starmer’s leadership. The man is then heard asking Starmer to leave the pub.
Links to the viral post and its archived version were reviewed as part of the research.
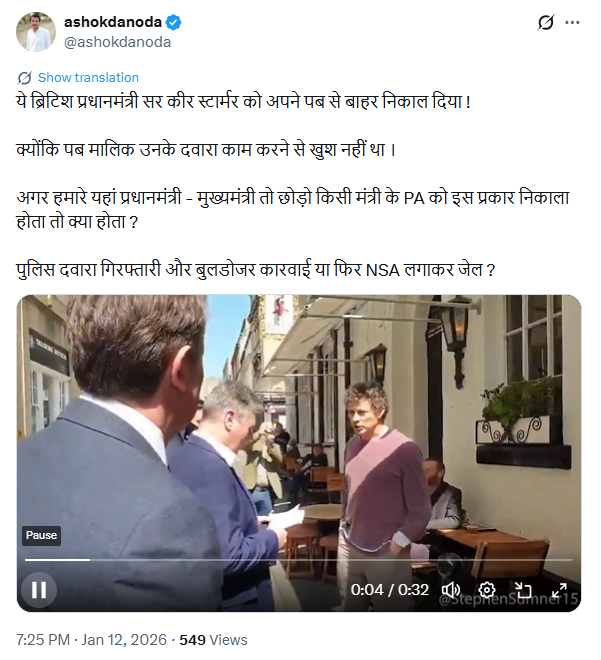
Fact Check
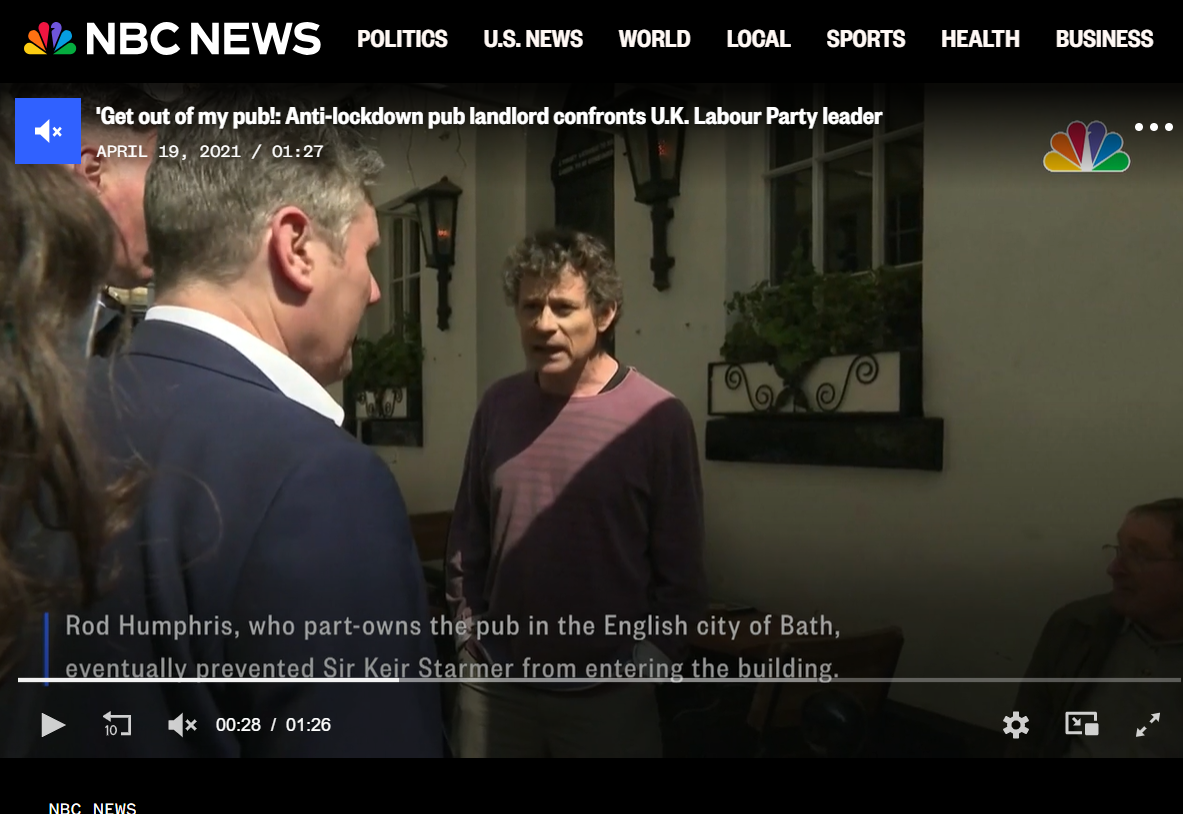
To verify the claim, we extracted key frames from the viral video and conducted a Google reverse image search. During this process, we found the same video posted on an X account on April 19, 2021.The visuals in the 2021 post matched the viral video exactly, clearly indicating that the footage is not recent.The original post described the incident as an event involving Labour Party leader Keir Starmer during his visit to the Raven pub in Bath, and included a warning about strong language used by the pub owner, Rod Humphries. Here is the link to the original video, along with a screenshot:

Further keyword searches led us to a report published by NBC News on April 19, 2021. According to the report, Keir Starmer, then the leader of the UK’s opposition Labour Party, was confronted and asked to leave a pub in the city of Bath. The pub owner reportedly accused Starmer of failing to oppose COVID-19 lockdown measures strongly enough at a time when strict restrictions were in place across the UK.
- https://www.nbcnews.com/video/anti-lockdown-pub-landlord-screams-at-u-k-labour-party-leader-to-get-out-of-his-pub-110466117702
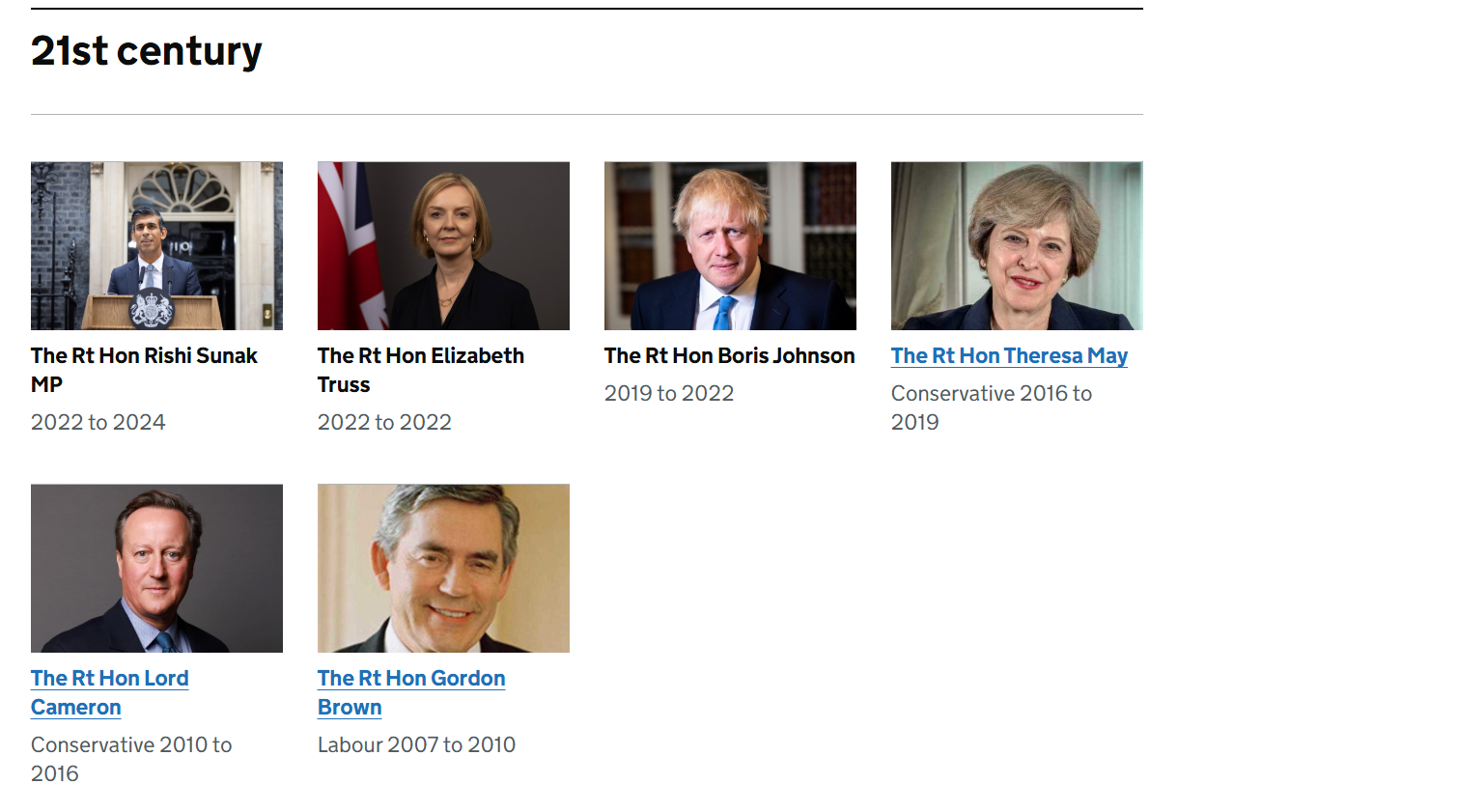
We also verified who held the office of British Prime Minister in 2021. Official UK government records confirm that Boris Johnson was the Prime Minister at that time, while Keir Starmer served as the Leader of the Opposition.
Conclusion
Our research confirms that the viral video is old and misleadingly presented. The footage is from 2021, when Keir Starmer was not the Prime Minister of the United Kingdom, but the opposition Labour Party leader. Sharing the video with the claim that it shows a current British Prime Minister being thrown out of a pub is factually incorrect.

Executive Summary
A video is going viral on social media showing ‘injured’ security personnel being carried into ambulances. The clip is being shared with claims that a terrorist attack recently took place in Kishtwar. The video surfaced nearly a year after the terror attack in Pahalgam on April 22, 2025, adding to confusion among users online. Research by CyberPeace Research Wing found that the claim is false. The viral video is actually from a mock drill conducted in Kishtwar, not a real terror incident.
Claim
An Instagram user ‘thenewjbharat’ shared the video on April 30, 2026, claiming that a terrorist attack had taken place again in Kishtwar.
https://www.instagram.com/thenewjbharat/
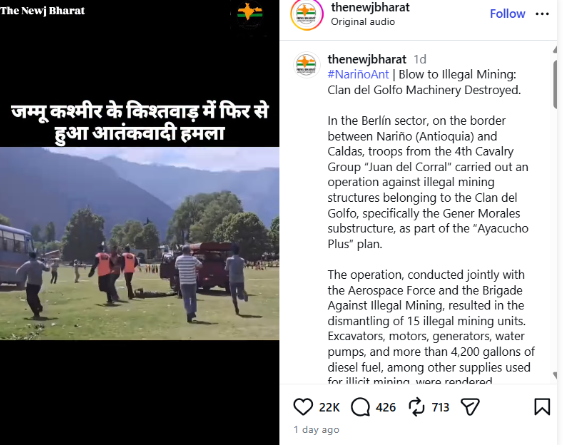
Fact Check
To verify the claim, we extracted keyframes from the viral video and conducted a reverse image search using Google Lens. This led us to the same clip uploaded on April 24, 2026 by an Instagram user ‘kishtwar_breaking_news’. According to the post, the video shows a mock drill conducted by local authorities to assess emergency preparedness. Officials and rescue teams participated in the exercise.

We also found a related news video uploaded on April 23, 2026, by the YouTube channel of Daily Excelsior, which featured visuals matching the viral clip. The report confirmed that the drill was carried out to evaluate readiness for emergency situations.

Conclusion
Our research confirms that the viral video does not show a real terrorist attack. It is footage from a mock drill conducted in Kishtwar and is being falsely shared with misleading claims.